Picky Data Sources: Next Steps Tweet
This is a post in the Picky series on its workings.
For quite some time now I have been thinking about rewriting the Picky data sources.
Although the ones that Picky use now work well, they do feel unelegant and unruby-ish.
But I’ll let you be the judge of that in the next part: How it works currently.
After that, I’ll talk about the problems with the current approach, and how I’d like it to be and how this could be possible to do. Feedback welcome, as always!
How does it work now?
At the moment, every index needs a data source. So you might write:
data_source = Sources::DB.new 'SELECT id, title, author, year FROM books', file: 'app/db.yml'
Index::Memory.new :books, data_source do
# categories ...
endIn the example, the data is coming from a database which is defined in app/db.yml (the file option).
Then, Picky’s indexer takes a snapshot of the data using your query and saves it in another table. The query can be anything, with joins and conditions etc.
Then, from this intermediate table, it will load batches of data, ordered in the way you ordered the results in your DB data source query.
So if you happened to say
SELECT id, titulo as title, author, year FROM books ORDER BY year DESCthen your results would be ordered by year, descending.
Picky is really data driven. If you sort the data in a certain way, it will be sorted like that in the results. (Well, inside each category combination, but let’s not go into that for the moment. Just know that it will help your user.)
By the way, don’t hesitate to use REGEXP, SUBSTRING or other functions in your SELECT statement to preprocess your data. It’s incredibly powerful to preprocess your data.
How does it work in the code?
What Picky does is instantiate an indexer for each combination of (index, category, source, tokenizer). So as an example, it is indexing the title category of a books index, with data coming from a db source, using the indexing tokenizer.
What the indexer first does is call the harvest(index, category) method on the data source, passing it the current index and category. That’s step 1.
The source can then use the index and/or category to get the data from its backend.
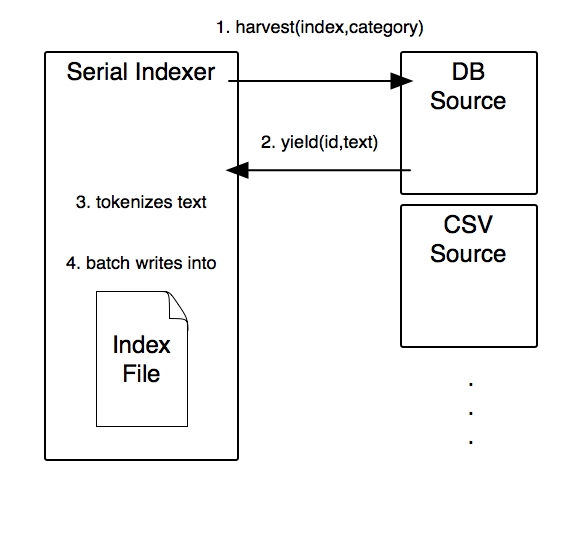
The source then gets the data from the backend and extracts the relevant parts. For the books index and title category it would do a select on the database using that information. Then, in step 2, it yields (slightly normalized) information back to the indexer, i.e. the id to index, and the data, the text to index.
The indexer then, in step 3, tokenizes the data as you defined with the default_indexing options, and finally, after some caching, writes it to the human readable index file.
The human readable index files are located in the Picky server directory index/{development,test,production}/books/ where you’ll find lots of files named category_....
I urge you to look at them! Lots of indexing questions can be answered by just looking at title_exact_index.json, for example.
Note that all index files are encoded in json, with the exception of the similarity indexes, which are Marshal dumped. So these are only human readable if you load them using Marshal.load, I’m afraid.
The problems
Although it all sounds nice, probably, there are three problems:
- The indexer is a “serial” indexer. Meaning that for each category, it asks the database to give it the data for the current category. So for each id, it asks the database for each data category separately. So for id 1 it asks for the title, then, later, for the author etc.
- In a similar vein, if I like to index correlated values, like geocoded data, that needs to be processed, it is simply not possible with the current indexer.
- It is a bit unwieldy seeming for a user, imho. This could be a sign that it could be more elegant.
Let’s look at the problems in more detail:
Serial Indexer
The first problem, that Picky is going to the database for each category, is of a performance nature. Although it does not have much impact (you probably haven’t noticed it yet), the way it is doing it now, it is still irking me that it does several return trips per id.
Correlated values not possible
Correlated values are not possible. What does this mean?
Let’s say that we have geocoded data, longitude and latitude. If you now try to do a geosearch by (ab)using the ranged_category method, you will experience problems, the closer to the pole the location is. While on the equator, Picky will search around it in a nice square.
But if you e.g. move to the north, since the longitudinal lines are closer and closer together, so will the ranged search distance. While 0.008 degrees might mean a kilometer on the equator, near the north pole it will be closer and closer to zero kilometers. So the square will be squished until it finally looks like a triangle.
Depending on the cartographic method used, this might not be a problem for you. But it certainly is if you’re looking at the whole earth. Now, if the categories were indexed together, Picky could recalculate the data for you such that the square area search (see one of the last blog posts) would be preserved.
One approach to how this could look is this:
Index::Memory.new :books, data_source do
geocoded_category :longitude, :latitude, 1.km
endIn a “parallel” indexer, Picky could load both longitude and latitude and do corrections on the longitude/latitude to preprocess the data so it would return correctly geocoded results.
Elegance
This is the part where I am most unsure about. But this
data_source = Sources::DB.new 'SELECT id, title, author, year FROM books', file: 'app/db.yml'
Index::Memory.new :books, data_source do
# categories ...
endjust doesn’t look good. Granted, you need to inject a lot of information in a few lines:
- Type of source (
DB) - Selection of data from the source (
SELECT) - Configuration of source (
file: 'app/db.yml')
But still, I’d love it to be much more elegant.
For quite some time, I wasn’t sure what to do. There isn’t a single nice interface of all the data sources. ActiveRecord does it this way, MongoMapper another etc. etc.
So Simon from Berlin asked me last night about whether I had experience with Picky and MongoMapper. I don’t, but it would certainly be cool to include it as a data source in one of the next versions of Picky.
I took a closer look at it. Similar to the new way in Rails 3, it uses a fluid interface, where some methods just modify the query, while some are “kicker” methods that actually do something:
User.where(:age.gt => 27).sort(:age).allMore here, http://railstips.org/blog/archives/2010/06/16/mongomapper-08-goodies-galore/. The all method at the end of a chain would be a kicker method, loading all objects.
That got me thinking.
How I would like it to be
Wouldn’t it be nice if we could just, instead of a data source, just pass any object as data source, so for example, with MongoMapper:
Index::Memory.new :books, User.where(:age.gt => 27).sort(:age) do
category :name, similarity: Similarity::DoubleMetaphone.new(3)
category :age
endQuite a bit sexier, imho. Since the result of the sort(:age) method is a proxy that offers kicker and non-kicker methods, the Picky indexer could now call each on it.
The contract would then be that each object that is yielded by #each must offer methods that are named like the categories (or named like the from option – e.g. category :name, from: surname).
So, in the above example, each User object would have methods #name and #age such that Picky could extract the data.
The cool thing with that would be that I could just pass in an Array of data. So, this would work (a, b, c all respond to #name):
Index::Memory.new :books, [a, b, c] do
category :name
endWhat would we have to do to make this work in Picky?
How to get there?
First of all, Picky would need to be rewritten, or at least be partially rewritten to use a “parallel” indexer, where each category would be loaded along with the others. So loading data set 1 would load title, author, year etc. at the same time. (Since some of these frameworks throw away the data after it has been yielded with #each)
The nice side-effect of this is that it opens real geosearch (or any combined category search) possibilities in Picky.
Probably, the frameworks offering the #each way would need to yield lazily, i.e. #each should not preload all the data before yielding as the data in question might be huge. Or maybe load it in batches.
How could we migrate from the current state to the new indexer?
I suggest that before instantiating the indexer, the index would first look at the source. If the source responds_to?(:each), the parallel indexer would be used. And if not, the “serial” indexer would be used, doing things the old way.
So the contract for parallel sources would be that they implement #each in a way that would load the data in batches and only yield objects which respond to the category names.
Let’s see if we can get this working soon :)
What I am wondering: Are we walking down a fool’s path? Comment if you have an opinion about that, please.
Possible problems
One problem could be that we lose speed since we’ll be instantiating lots of objects that respond to the categories. On the other hand, the return trips would not be necessary anymore.
Another problem is that since we’re just depending on #each, we couldn’t pass the source the index and category anymore. So choosing the right data would be the responsibility of the user. I do not think this to be a big problem.
Final remarks
Although I’d like to make it more elegant, I’d still like to preserve the old way of doing things. Sure,
Index::Memory.new :users, User do
category :name, similarity: Similarity::DoubleMetaphone.new(3)
category :age
endmight look nicer than
user_source = Sources::DB.new 'SELECT id, name, age FROM users', file: 'app/db.yml'
Index::Memory.new :users, user_source do
category :name, similarity: Similarity::DoubleMetaphone.new(3)
category :age
endI’d like the old way to be available, since doing the right SELECT is incredibly useful.
Conclusion
So we’ve seen
- how Picky data sources work now.
- how they ought to work.
- that
#eachwould be more ruby-ish. - how a migration path could look like.
Hope you learnt something new!
Next Picky 2.2.0Share
Previous Searching with Picky: In the Terminal