Picky Update Performance Tweet
This is a post about Picky performance when updating realtime indexes.
tl;dr
In the single-process/single-threaded case on one core of a 2.66 GHz i7 Macbook Pro, Picky realtime index update performance ranges from 500 updates/s to 25’700 updates/s. Around 2’300 to 5’100 updates/s for a default case.
Quick realtime index refresher
If you didn’t know, since 3.2.0, you can add/remove/replace (update) objects from and to a Picky index. In realtime.
For example,
index = Index.new :things do
category :text
end
index.replace thing_with_text_methodwould replace the index data for the thing_with_text_method.
If you added a search interface for the index,
things = Search.new indexyou could also search for it and it would return different things if you changed the index in between.
things.search "some thing" # => Finds the thing.
index.remove thing_with_text_method.id
things.search "some thing" # => Finds it no more.The Setup
All numbers are valid for a 2.66 GHz i7 Macbook Pro (one core of it) with 4GB 1067 MHz DDR3 RAM, using Picky 3.5.3 on ruby 1.9.3p0 (2011-10-30 revision 33570) [x86_64-darwin11.2.0].
For testing performance, we randomly pregenerated a large set of objects with methods id, user (8 random characters), text1 (20 random characters, 26 from the alphabet, 5 spaces), and text2, text3, text4 (see generation of text1).
Then, we used the following index. To make everything easier, we used a config variable to enable/disable categories.
include Picky
config = 0 # 1, 2, 3, 4.
index = Index.new :things do
weights = Weights::Default # These configurations were changed.
partial = Partial::Default #
similarity = Similarity::Default #
if config >= 0
category :user,
weights: weights,
partial: partial,
similarity: similarity
end
if config >= 1
category :text1,
weights: weights,
partial: partial,
similarity: similarity
end
if config >= 2
category :text2,
weights: weights,
partial: partial,
similarity: similarity
end
if config >= 3
category :text3,
weights: weights,
partial: partial,
similarity: similarity
end
if config >= 4
category :text4,
weights: weights,
partial: partial,
similarity: similarity
end
endIf config was for example 3, Picky used categories :user, :text1, :text2 and :text3.
We then varied the configurations for weights, partial, similarity. Weights control how the categories are weighed. Partial how you can search partially (like just for the first character or only for the exact word). And similarity defines if you can search for similar words to the one you entered.
We indexed until the average update/s value stabilized.
The Chart
A quick explanation of the legend: It is ordered weights/partial/similarity. From fastest to slowest, the options were…
Weights (2): Constant, Default/Logarithmic.
Partial (3): None, Default/Postfix(from: -3), Postfix(from: 1).
Similarity (3): Default/None, Soundex(3), DoubleMetaphone(3).
We did not explore all combinations. The numbers were rounded down to the nearest hundreds.
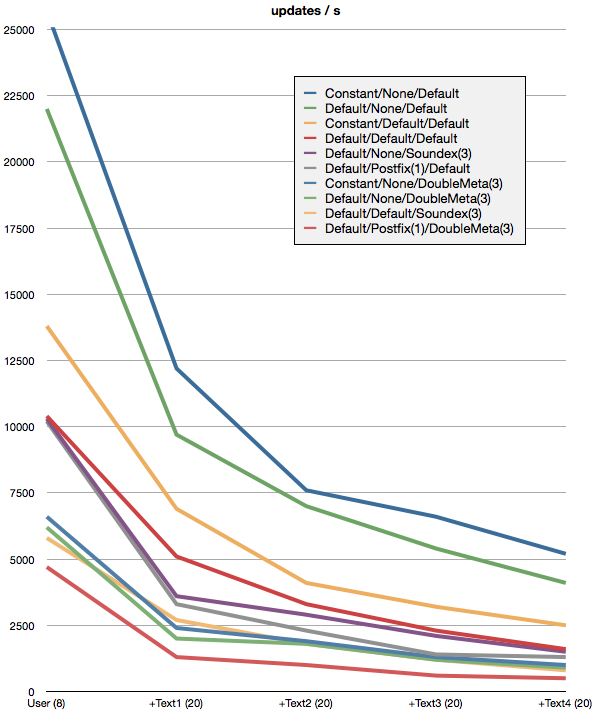
From left to right, we first indexed just the user category, then successively added text1, text2, text3, and text4.
The baseline (not shown), when no category was defined, was 212'000 updates/s.
The absolute winner is indexing just the 8 character user category, with a constant weight, no partial indexing, and no similarity, at 25'700 u/s.
Usually though, you’d want Picky’s weighing and scoring to be used. So, the same scenario, with no partial/no similarity yields a speed of 22'000 u/s. In a more realistic case with 3 text categories and 1 user category, it is 5'400 u/s.
For added convenience, you’d use the default partial algorithm, which also includes parts of words, from the 3rd last character of a word to the last. With default weighing, and no similarity, this yields 1'600 up to 10'400 u/s. This is with all settings to default (Default/Default/Default), as if you had defined nothing:
category :text1 # etc.If you are interested in similarity, but not partial, the numbers range from 900 to 6'200 u/s.
The most brutal case, standard weighing, full partial, and best similarity costs dearly: Only 500 up to 4'700 updates per second.
If you like pure numbers better than a graph, here’s a table for you:
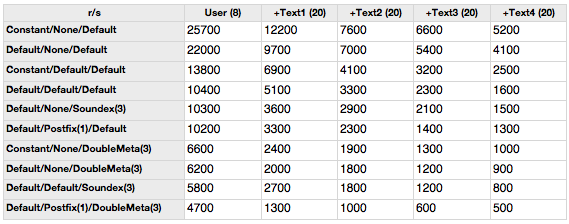
Now, let’s all “jump” to conclusions! ;)
Conclusions
First of all, we are very happy with the numbers. We did expect a much lower performance. (Sorry, Picky)
How Picky weighs and scores the data didn’t impact the results much. This is no surprise, as no string manipulation is done.
Partial indexing impact was what we expected. Around a 40% to 60% reduction from (Default/None/Default) to (Default/Default/Default) in speed depending on how many text categories were indexed. The jump to (Default/Postfix(from: 1)/Default) – an all inclusive partial – is around 50% to around 70%.
The worst impact comes from similarity indexing: Using similarity brings down indexing speed to about 25% (no partial) to 50% (also using partial).
The big takeaway: Text categories with much content are most important, followed by whether you do similarity, followed by whether you do partial searches. Weighing almost plays no role.
The bigger takeaway: Picky is fast when updating indexes. And does it in realtime. On Ruby.
Next Picky Search Performance (Backends)Share
Previous Search Engine in a Script