Picky Search Performance (Backends) Tweet
This is a post about Picky performance when searching in various backends.
But first, a picture that was taken during the performance tests:

How is taking this picture possible you ask? I am writing this from a hospital.
Heh, no. Not really.
tl;dr
In the single-process/single-threaded case on one core of a 2.66 GHz i7 Macbook Pro, Picky’s search performance ranges from 0.0001s for a single-word query on the memory backend to 0.01s for a three word query on the Redis backend. Around 0.0003s per query on the memory backend for a more realistic case.
Why?
We are currently working on designing the Picky backends, amongst other ideas, to enable realtime indexing.
If you want to contribute a backend, please do!
The raw data
In descending order of performance, we evaluated four backends that are available: Memory, File, SQLite (graciously donated by Roger Braun) and the Redis backend.
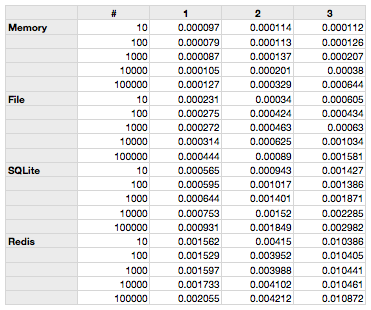
The 10 – 100000 show the number of objects in the database. The columns 1-3 denote the complexity. 1 is just using one word, and 3 means we looked for three words.
We were wondering about the Redis backend a bit, and also the file backend (see below). Memory and SQLite are as expected. What did we expect?
Expectations
All of the following charts show the three different complexity levels in various index sizes (objects indexed).
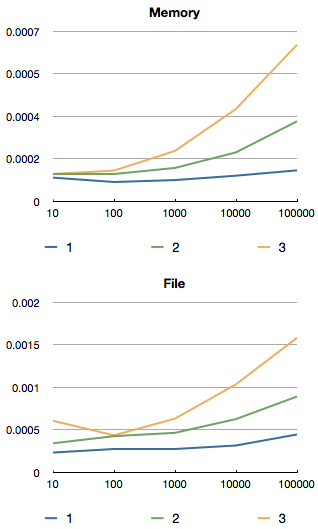
Since the memory backend runs fully in memory (duh), we get the best performance there. It’s all fully in memory, so none of the dirty slow stuff even gets touched.
With the exception of that dirty old man that touches everything, the Ruby Garbage Collector.
The file backend (very naïve, see here) surprised us a bit, since we are actually loading JSON encoded data from a file.
However, seeking in Ruby and decoding with Yajl Yajl::Parser.parse IO.read(cache_path, length, offset) is apparently quite fast.
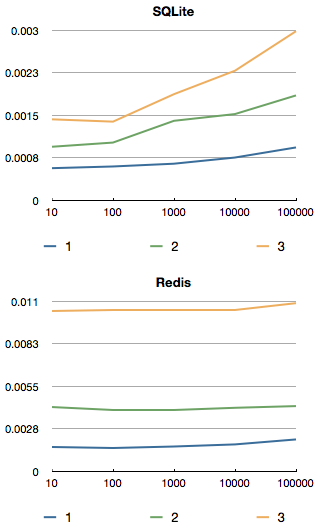
Tests of a first draft of a SQLite database (by Roger Braun) show lots of promise as well.
Redis is rather slow, as expected. However, this is not just Redis’ fault. The current implementation does three roundtrips per simple internal query.
For example, in the three words case, and having four different categories each word can be in results in 36 up to 72 roundtrips. And for that, the Redis backend performs very well.
With the arrival of Redis 2.6.0, we will make use of the Lua scripting and the EVALSHA command to divide the number of roundtrips by 3.
That will, for a four category, three word query result in only 12 up to 24 roundtrips. Still a lot, but this should prove to be much faster.
One Redis behaviour that surprised us a lot was that for the “complexity 3” case where we looked for three words, the performance of Redis in the graph remains constant. Why does it remain constant, and why doesn’t it show the same behaviour?
Turns out, the curve does exactly the same, but is squished, because the complexity tends to make a large difference to the baseline.
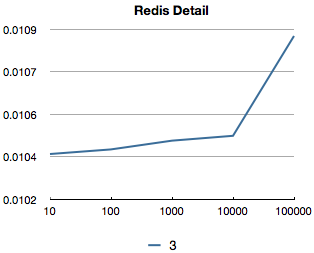
If you look at just the “complexity 3” case (here in blue instead of yellow), we can see the same behaviour.
What happens is that for the multi-word case, the amount of expensive roundtrips shoots up. The amount of combinatorics and calculations that Picky does is just the cherry on top of a large roundtrip cake.
For four words, this would be even worse: We would have to search for the line around 0.02s.
We hope to reduce this greatly with Redis 2.6.0 and expect a 3-4x speed increase.
Comparisons
Comparing each of the complexity cases (1 word, 2 words, 3 words) for the backends, they are nicely evenly spaced apart.
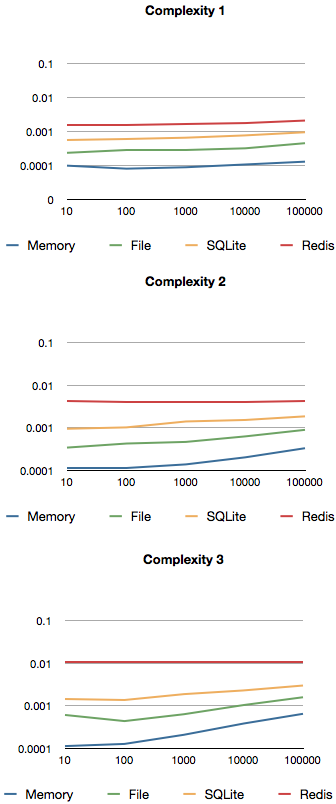
That is, on a log scale. From Memory to File, from File to SQLite, from SQLite to Redis we each have about a 2x query time increase. Comparing Memory and Redis, we thus get about a 8x increase (actually, more like 10x).
While for the one word case, the data remains quite flat as the index size increases, the impact on performance is very noticeable in the three word cases.
A note on the index sizes: Yes, 100’000 entries is not a very realistic size (we do not have access to large servers yet). But it is enough to see Picky’s behaviour regarding speed. However, the curves behaviour is quite predictable and can be extrapolated from the curves seen above.
For example, if you extend the curve of the memory case to 1000 times the size (to 100’000’000 entries): The complexity case 1 it arrives at 0.0002s, in the complexity case 3, at around 0.005s.
In the case of 15’000’000 entries, this is exactly what we found to be true for the memory case. Please see use case 1 on the Picky page.
Selecting a backend
What does it mean for you when choosing the backend?
- If you need a realtime index, then the only backend that supports this is the
Memorybackend (current version at the time of this post is 3.5.4). We are working on getting the others up to speed, but this is what’s there for now. - If you need persistence and/or distributed Pickies, we recommend the Redis backend. Speed may not be fantastic, but from Redis 2.6.0 on it will be quite a bit faster. We predict around 3-4 times faster.
- The
FileandSQLitebackends are still in development. Use theFilebackend when you have a static index and do not want to use too much memory. The same holds for theSQLitebackend, with the improvement that you have all the SQLite tools at your service.
As usual, it’s a tradeoff between speed, space, tools etc.
The code
The code for these tests is here:
http://github.com/floere/picky/blob/master/server/performance_tests/search.rb
We generated sets of 10-100000 indexed things, each with 4 categories and an id. Then we randomly selected data from the indexes and in roughly half of the cases are searching for just part of the word for which Picky uses a partial search.
We ran 100 random queries each, and divided the resulting time by 100 to get an average per-query-time.
A note on combinatorial search engines
Combinatorial search engines are hard to performance test.
If in a phone book search on Picky you search for “peter paul victoria”, Picky evaluates what you are most likely looking for. This involves a fair bit of calculation.
In the mentioned case, if “peter” can be a first name, name, street, city, and the other words are similarly ambiguous, then Picky has to look at all the possible combinations and has to find out which one is the one that is most likely, based on the weights and boost you defined.
Now, this is very dependent on the data underlying it. So I tried to use relatively standard data.
So, in closing, it must be said that it is hard to compare this style of search engine to one of the generic search engines. But Picky would really like to take one on soon ;)
Next Picky 4.0Share
Previous Picky Update Performance